Kafka basic intro
本文共 600 字,大约阅读时间需要 2 分钟。
Refrence:https://zhuanlan.zhihu.com/p/20772147?refer=bittiger
· 21 天前
数据集成超麻烦,你往往会发现你用在收集整理数据的时间是最多的,像这样:
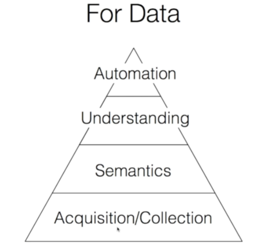
数据有两种:一种是数据库数据,比如用户、产品等关系型数据;另一种是实时的数据,比如数据(包括用户点击、浏览等),应用数据(包括CPU的使用等)和log。
如果不同的数据用不同的数据库来存储监控,不同应用要从不同的地方取得需要的数据,就会这样(炸了):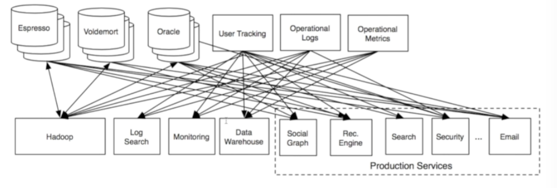
所以Kafka出现了,把数据集成这个环节做的简洁高效,像这样: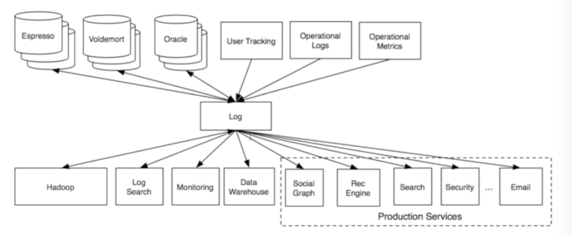 Kafka把这个过程抽象了一下变成了这样(眼熟不眼熟,就是生产者消费者模型呀):
Kafka把这个过程抽象了一下变成了这样(眼熟不眼熟,就是生产者消费者模型呀):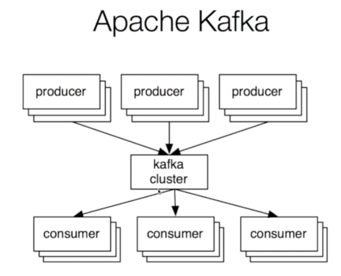
Kafka最核心的是log,什么是log呢,log就是记录什么时间发生了什么事。当log很多就要做成分布式,对log分区,每个partition是独立的、不交互的,这样避免了partition之间的协调,非常高效。像这样: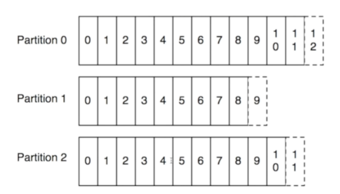 工作流程就是数据源(生产者)将数据写入log,消费者从log中提取数据,log起到了一个消息队列的作用。所以Kafka就是一个基于分布式log实现的,具有发布/订阅功能的消息系统。
工作流程就是数据源(生产者)将数据写入log,消费者从log中提取数据,log起到了一个消息队列的作用。所以Kafka就是一个基于分布式log实现的,具有发布/订阅功能的消息系统。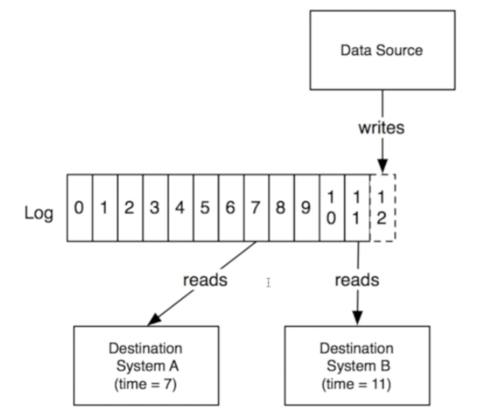
因为Kafka用log记下了所有时间发生的所有事,任何一个状态都可以被恢复出来。Kafka的理念就是实时处理就是log加计算(Job),像这样: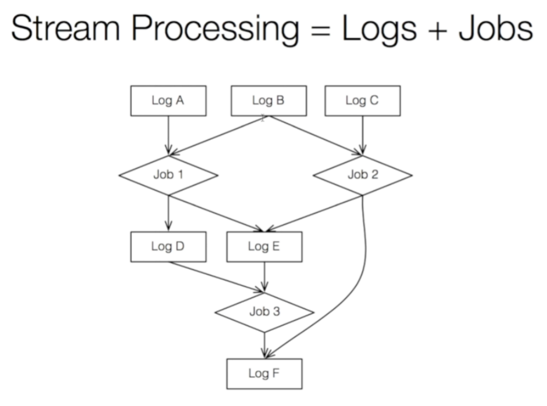
本文整理作者:Mengying Tian,
转载地址:http://kqhbi.baihongyu.com/
你可能感兴趣的文章
[Mac]Mac 操作系统 常见技巧
查看>>
苹果Swift编程语言入门教程【中文版】
查看>>
捕鱼忍者(ninja fishing)之游戏指南+游戏攻略+游戏体验
查看>>
iphone开发基础之objective-c学习
查看>>
iphone开发之SDK研究(待续)
查看>>
计算机网络复习要点
查看>>
Variable property attributes or Modifiers in iOS
查看>>
NSNotificationCenter 用法总结
查看>>
C primer plus 基础总结(一)
查看>>
剑指offer算法题分析与整理(一)
查看>>
剑指offer算法题分析与整理(三)
查看>>
部分笔试算法题整理
查看>>
Ubuntu 13.10使用fcitx输入法
查看>>
pidgin-lwqq 安装
查看>>
mint/ubuntu安装搜狗输入法
查看>>
C++动态申请数组和参数传递问题
查看>>
opencv学习——在MFC中读取和显示图像
查看>>
retext出现Could not parse file contents, check if you have the necessary module installed解决方案
查看>>
pyQt不同窗体间的值传递(一)——对话框关闭时返回值给主窗口
查看>>
linux mint下使用外部SMTP(如网易yeah.net)发邮件
查看>>